Download ASPED.b
We are currently preparing the publicly available version of ASPED.b.
| File | Description | Size | Download |
|---|---|---|---|
| Mini Test Data Package |
ASPED.b Session 1 Mini Package
|
* | Download link will be available shortly. |
| Audio Data Package | ASPED.b Session 1-4 Audio Recording (.MP4) ASPED.b Session 1-4 Annotation (.CSV) |
240 GB (Approx. 1 TB after decoding) | Download |
| Video Data Package | ASPED.b Session 1-4 Video Recording (.MP4) | Approx. 1 TB | Download |
| Metadata |
ASPED.b Session 1-4 Metadata (.XLSX)
|
989 KB | Download |
Data Description
1. ASPED.b Session Details
| Session | Date | Location | # of Video Recorders | Total Video Frames | # of Audio Recorders | % of Bus Obstructed Frames |
|---|---|---|---|---|---|---|
| Session 1 | July 26-28, 2023 | Fifth Street | 6 | 916,825 | 8 | 2.32% |
| Session 2 | August 9-11, 2023 | Fifth Street | 6 | 932,842 | 7 | 2.47% |
| Session 3 | November 7-9, 2023 | Fifth Street | 4 | 536,822 | 4 | 4.96% |
| Session 4 | November 28-30, 2023 | Fifth Street | 4 | 560,024 | 5 | 2.51% |
2. Audio Data
-
|--Session_07262023
|-- FifthSt_A
|-- Audio
|-- [Recorder1]
|-- 0001.flac
|-- 0002.flac
...
...
|-- [Recorder2]
|-- FifthSt_B
|-- FifthSt_C
|-- FifthSt_D
|-- FifthSt_E
|-- FifthSt_F
|--Session_08092023
|--Session_11072023
|--Session_11282023



ffmpeg -i /PATH/TO/FLAC.flac -o /PATH/TO/WAV.wav 3. Video Data
-
|--Session_07262023
|-- FifthSt_A
|--Video * each location has one camera
|-- 0001.mp4
|-- 0002.mp4
...
|-- FifthSt_B
|-- FifthSt_C
|-- FifthSt_D
|-- FifthSt_E
|-- FifthSt_F
|--Session_08092023
|--Session_11072023
|--Session_11282023
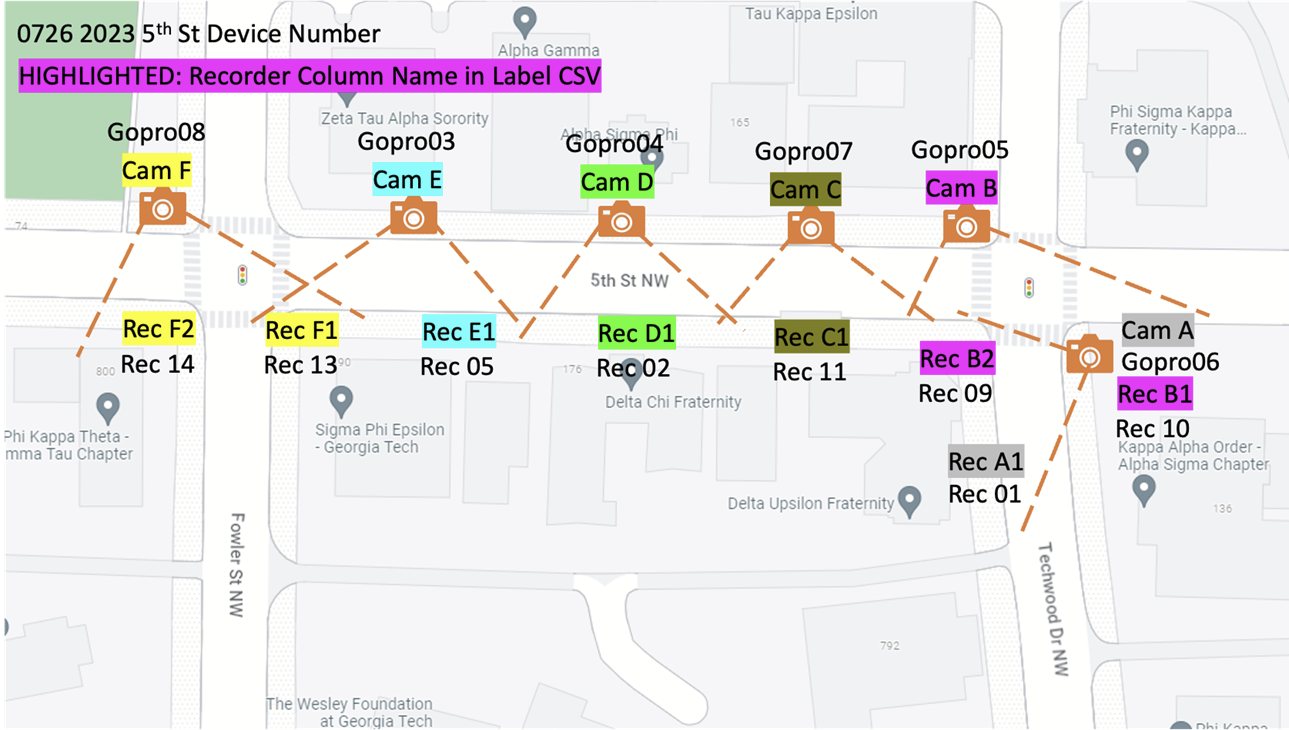
We set up six video cameras to capture footage to determine the actual count of pedestrians walking past the audio recorders. Each recording session captured almost 41 hours worth of footage at a rate of 1 frame per second, leading to a combined total of approximately 34 days of recordings in the entire dataset among 20 different video recording sessions. Each camera covered multiple audio recording devices, as depicted in the following map. You can find the map in the metadata file.

4. Annotation Data
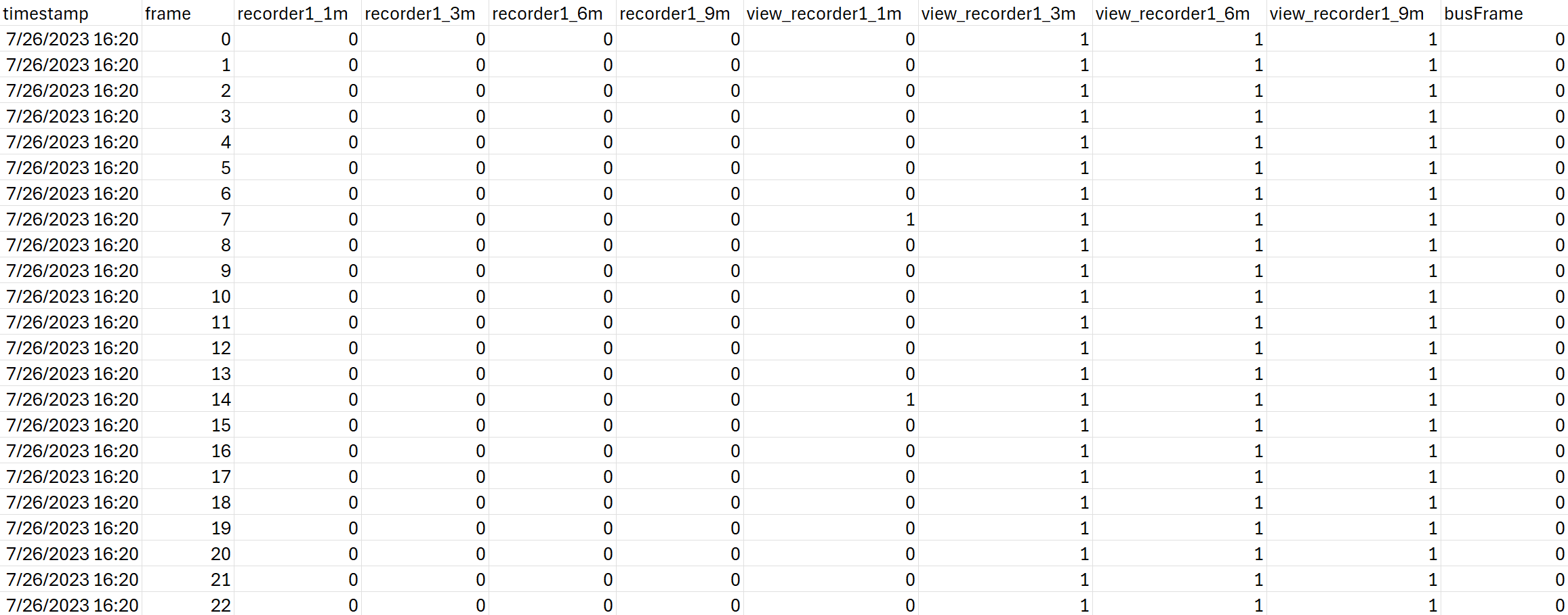
Each annotation file lists the number of detected pedestrians within 1, 3, 6, and 9-meter radii around the monitored audio recorders (indicated by the "recorder" columns).
For ASPED.b, the sample annotation file also includes info regarding whether an audio recorder contains a vehicle inside of the 1, 3, 6, or 9-meter radii
(indicated by the "view_recorder" columns). Lastly, the annotation file also indicates whether the camera was obstructed by a bus in a specific frame (indicated by the "busFrame" column).
 We used the Masked-attention Mask Transformer (Mask2Former) model to detect and annotate the pedestrians passing by the audio recorders in the video recordings,
with a prediction accuracy threshold of 0.7. For this research, we used the Mask2Former version from OpenMMLab,
which was trained using the Microsoft COCO dataset.
We used the Masked-attention Mask Transformer (Mask2Former) model to detect and annotate the pedestrians passing by the audio recorders in the video recordings,
with a prediction accuracy threshold of 0.7. For this research, we used the Mask2Former version from OpenMMLab,
which was trained using the Microsoft COCO dataset.
5. Code
We have also provided PyTorch util files to help you work with the ASPED dataset. These files handle the data loading, processing, and preparation for model training.
| File | Description | Download |
|---|---|---|
| Dataset File |
|
Download |
| DataModule File |
| Download |